Kako dupli i kopirani sadržaj utiče na SEO? - eksperiment No1
Google stalno radi popis sadržaja na internetu (crawling), analizira prikupljene podatke i formira bazu odakle će prikazati rezultate kada neko nešto traži.
Najmanje što mu je potrebno je da jednu istu stvar analizira i stavlja u bazu više puta. Zbog toga se ne preporučuje da kopirate sadržaj sa drugih izvora.
Jednostavno, Google će te stranice vašeg sajta potpuno ignorisati i neće ih indeksirati. Ono što nije u indeksu, ne može se ni prikazati na rezultatima pretrage.
To je po teoriji.
Tokom septembra sam testirao da je je to zaista tako u praksi.
Eksperiment No1 - Sastaviti članak uzimajući pasuse sa više drugih sajtova
Za ovaj eksperiment sam pokupio sadržaje sa četiri izvora. Uzeo sam ravnomernu količinu reči, oko 230. Gotov članak je imao 950 reči, što je iznad proseka u odnosu na ostale tekstove koji se rangiraju za ključnu reč. Uneo sam svoje naslove (h1, h2). U tekst sam dodatno uneo četiri linka, od kojih su tri interna, a jedan vodi na sajt na engleskom.
Nakon objave članka sam odmah odradio Inspect URL i zatražio indeksiranje. Tekst je indeksiran u roku od 10tak minuta.
Takođe sam odmah usmerio spoljni link ka sadržaju. Uradio sam Inspect URL i te strane što znači da je Google odmah pronašao backlink.
Četiri dana nisam ništa pipao. Pogledao sam Search Console i video sam da je strana počela da dobija impresije i klikove. Za grupu ključnih reči koju je stranica ciljala sam dostigao poziciju no8 (dno prve strane SERP-a).
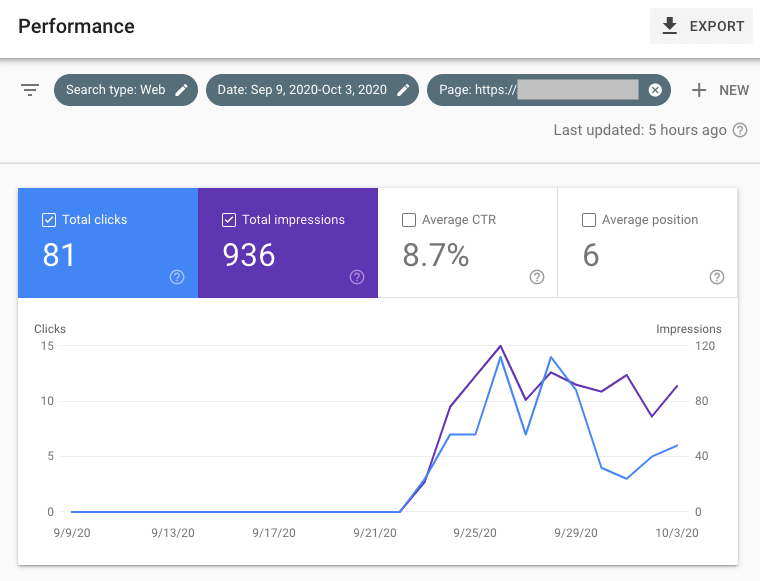
Učinak stranice koja ima duplu sadržaj preuzet sa više izvora.
Tekst nisam dirao do 4. oktobra 2020. kada sam odlučio da da obrišem.
U međuvremenu je prosek pozicija ključnih reči koje su donosile klikove i prikaze skočila na 3. Prosek pozicija od početka eksperimenta do kraja je okruglo 6.
Strana je bila aktivna dvanaest dana.
Iskreno verujem da bi par dodatnih linkova postavilo ovu stranu na vrh Google rezultata pretrage.
Šta bi drugačije odradio kada bi ponovio eksperiment?
Definitivno ne bi usmerio dolazni link ka sadržaju. Baš me interesuje da li bi postigao ove rezultate bez backlinka.
Takođe, 900+ reči je overkill ako se poredi konkurencija. Svi ostali imaju manje teksta. Izgleda da kompilacija sadržaja sa prve strane SERP-a i izrada jednog obimnijeg sadržaja dobro funkcioniše.
Voleo bi da mogu mesecima da držim ovu stranu objavljenu i da vidim kako bi se kretale pozicije, ali ne želim da upadnem u neprilike i tužbe koje bi sigurno nastale kada bi konkurenti videli da sam im uzeo sadržaj.
Možda bi vam značilo da znate da su meta podaci i semantika koje sam uneo su bili perfektni 👌
Dobar title, h1, h2 su sigurno pomogli. Zanimljivo bi bilo videti kako bi se tekst ponašao da sam uneo slični title kao što ima većina konkurenata.
Zaključak
Google ne ignoriše u potpunosti svaki dupli sadržaj koji nađe. Čak se možete jako dobro rangirati tako što pravite sadržaj uzimanjem pasusa sa više izvora. Posebno ako kopiranom sadržaju pomognete sa par dolaznih linkova.
Postoji verovatnoća da će vam Google obrisati stranicu iz indeksa nakon nekog vremena, ali mislim da je to malo verovatno na domaćem Internetu (ex-yu okruženje).
Konačno, moja preporuka je da sve ovo ne radite! Uzimanje sadržaja bez saglasnosti autora podleže pravnim posledicama i u domaćoj praksi postoji na desetine primera uspešnih tužbi u oblasti zaštite intelektualne svojine i odbrane autorskog prava pojedinaca i kompanija.
Uložite sat-dva i sami napišite sadržaj ili angažujte nekoga za to.
Naredni eksperiment
Tokom oktobra ću pokušati da rangiram kopiran sadržaj preuzet sa samo jednog izvora. Plan je da desetak dana ne usmeravam dolazne linkove, a onda da dodam nekoliko i pratim učinak stranice.
Cilj je da jakim linkovima pokažem da je "moj" sadržaj jači od originalnog i da potpuno preskočim "original" na veći broj ključnih reči za koje taj sadržaj rangira.
Ne brinite, neću ukrasti tuđi sadržaj, već ću ceo eksperiment uraditi sa jednim mojim starih tekstom na temu nekretnina.
------
Odricanje od odgovornosti: Test sam izvršio potpuno svestan mogućih pravnih posledica. Cilj eksperimenta nije bilo nanošenje štete originalnim autorima sadržaja već istraživanje načina na koji funkcioniše Google algoritam pretrage.
Nenad Pantelić
Nenad je stručnjak za SEO, PPC i web analitiku. Od 2009. godine kroz ruke mu je prošlo na stotine sajtova kojima je pomogao da dođu do pozicija, poseta, konverzija i profita. Piše za Netokraciju i RNIDS. Do sada je izlagao na preko dvadeset konferencija na teme digitalnog marketinga. Trenutno vodi projekat Strap Hunter. Vlasnik je kompanije Blueberry Digital.